Start up the InMemory ETL tool:
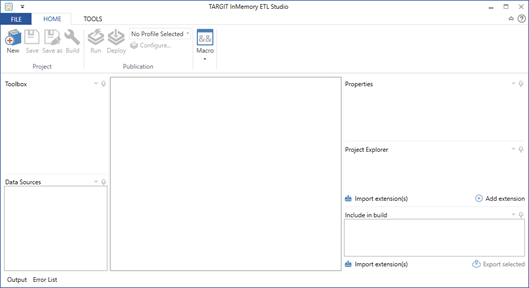
Before we get started, we might want to look into some of the general options for the ETL tool:
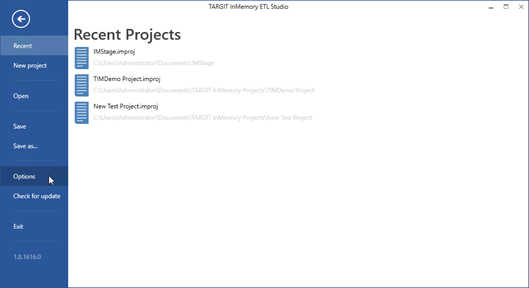
For instance, you may want to change the Default project folder to a more accessible location. Otherwise, it will stored in Documents for the current user.
With these initial steps in place, we can now create our first ETL project:
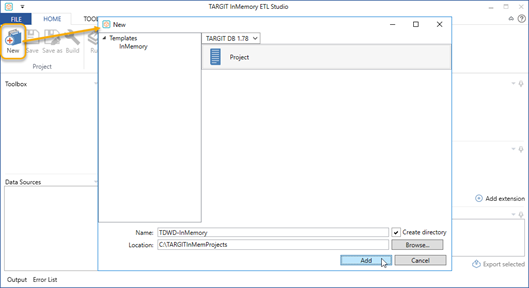
In order for the project to work, we will need to configure a publishing folder. Initially, you can use the ‘Public’ folder.
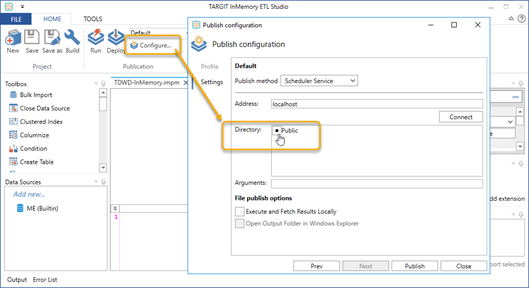
You might try to hit ‘Publish’ right away – just to check that the publishing process succeeds without errors. However, it will be an empty database since we haven’t set up any import scripts yet.
Before setting up any import scripts, first we will need to connect to our ”Source data” – the DD_W1_01 database on the SQL Server:
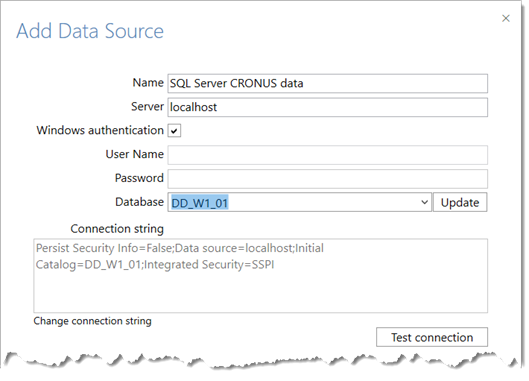
Provide a proper name for this connection, and specify the server name on which it is running – ‘localhost’ will do if it is on the same server. You should then be able to select the DD_W1_01 database from the drop down list.
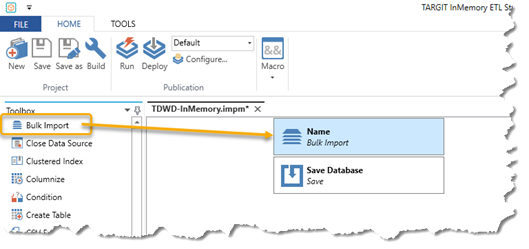
From the Toolbox on the left hand side, we can now start dragging some tasks into the Project area. For this first test run, we may limit it to the Bulk Import task and the Save task. All projects must always conclude with a Save task.
Select the newly added Bulk Import task and, in properties on the right hand side, select the SQL Server data source and click the Tables Configure button to start selecting relevant tables from the data source.
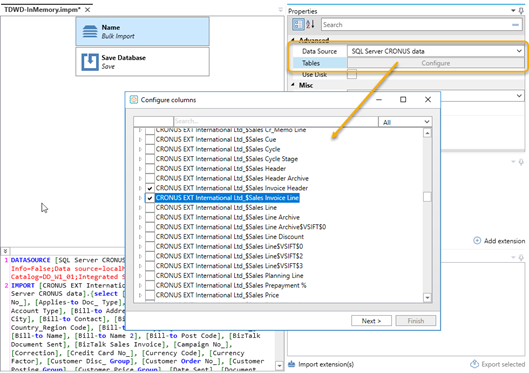
For this first test run, we may get going with selecting just a few tables:
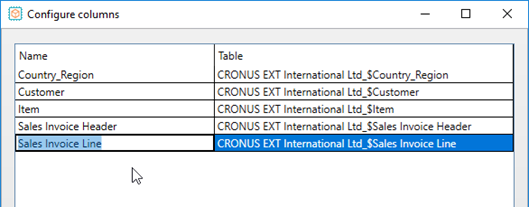
Notice that the table names on the left hand side have been truncated to a simpler naming convention – for ease of reference later on.
Next step would be to run the project which would then start populating the InMemory database with data from our selected tables.
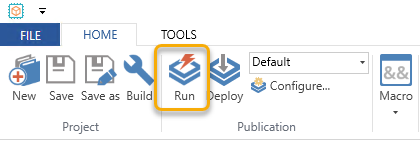
If you should wonder what some of the buttons actually mean:
- Build. Use this button to build the script files without running them. Why should you do that? I don’t know.
- Run. Use this button to (build and) run the script files from the current project. In our example, this is what we need to make sure that we populate our InMemory database with data.
- Deploy. Use this button to deploy the script files to the InMemory Scheduler. So, if you made changes to your project, and you want those changes to reflect – also when the Scheduler runs its automatic jobs – then you should deploy the project
Hitting the Run button will try to build and run the project with all of its current tasks. You can follow the individual steps and their success/failure in the Output section at the bottom of the ETL tool.
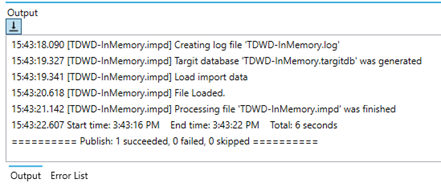
Once the project has been published successfully, you can use the InMemory Query Tool to connect to the InMemory server:
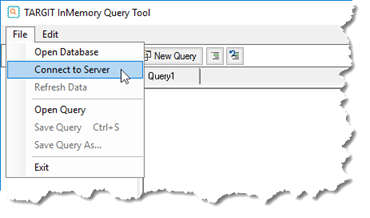
The connection details include the ‘default’ user and this user’s password. Something you should remember from the installation. Hint: Pa$$W0rd.
Eventually, once connected to the server, you should be able to query data in the available databases and tables:
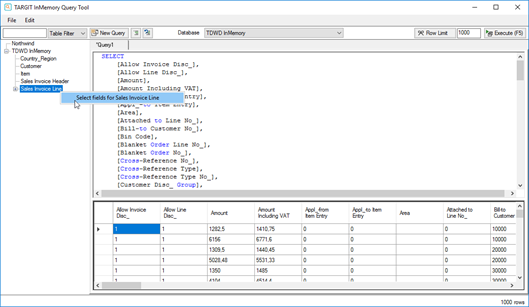
The Query Tool allows you to execute any valid query. If you know how to write T-SQL queries, you will also know how to use the InMemory Query Tool.
Comments
Please sign in to leave a comment.