When you add a lot of different data sources and cubes to your data discovery environment there are a few things that could help in keeping the environment healthy and also avoid getting misleading results form the data models you make.
- Clean up with regular intervals
You need to make sure that there are no unused data sources and cubes that takes up space and makes it hard to get an overview of the usage.
So make it a rule to go through the environment and check if everything is actually being used. - Make sure the refresh schedule is set correctly
On all data source types (except Excel and CSV files) there is a scheduler set to a certain refresh schedule:
If you click the Set button you can change the schedule to the correct intervals
Some sources may not need hourly or daily refresh - so set them to what's needed:
- NEVER make direct relations from fact table to fact table
This type of relation can NEVER be correct:
You might get a right result in some cases - but changes in data can easily "break" such a model.
Also it can potentially use a lot of memory when you do this.
Relations should also go from a fact table to a dimension tabel with unique values - and if 2 fact tables have a common denominator, you need a dimension table with only unique occurrences of this field "in between" these 2 fact tables.
This is the correct principle - a unique list in the middle: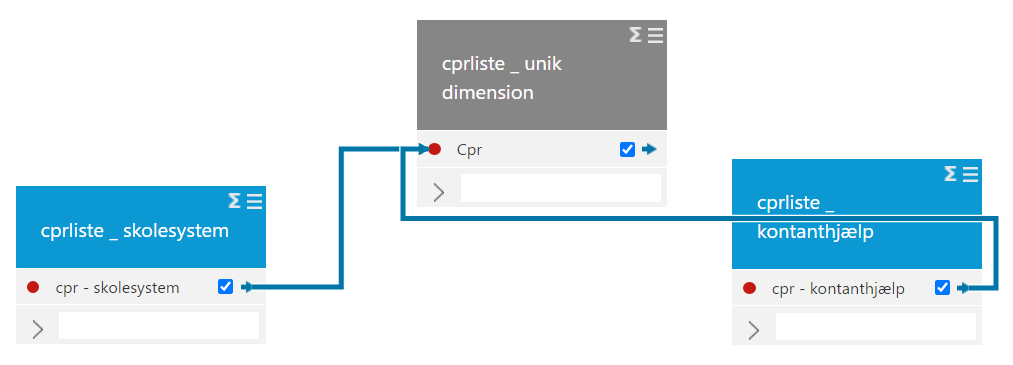
- Consider placing your Data Discovery on a dedicated server
When it's placed on your "normal" TARGIT Server it's using the same resources that the TARGIT Server needs for making queries for you. - Clean up metadata
In the cube editor there is a "hamburger menu" - the 3 horizontal lines - click that and choose the Attribute settings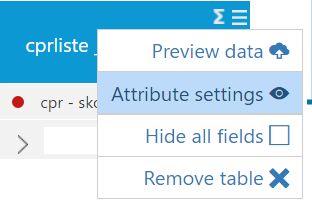
Now you can finetune what you want to keep and what the users shouldn't be bothered with in terms of dimension and measure types: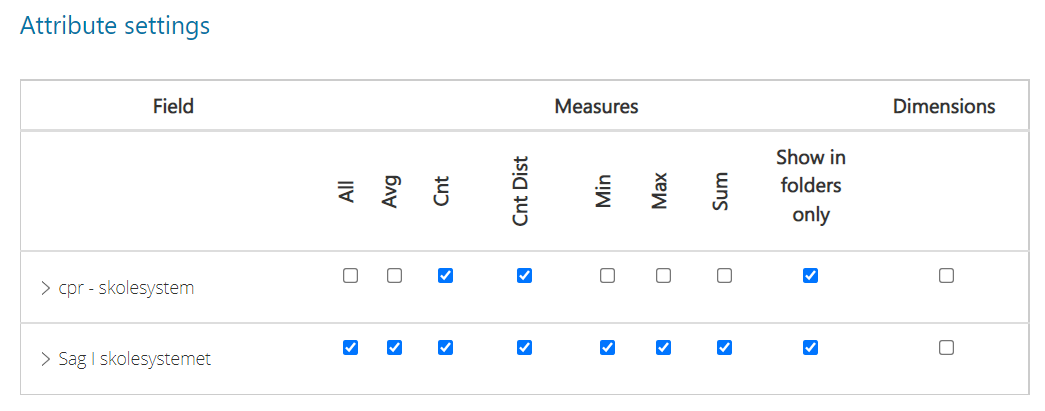
- Avoid too large data models
Data Discovery works best with single files or models limited to a few data sources built into a data model.
If you need to build "real" data models, you should probably consider TARGIT InMemory instead of Data Discovery.
Please comment and ask questions about this article - and maybe add your own best practice rules for Data Discovery in TARGIT.
Comments
Please sign in to leave a comment.