Aggregations are designed from the Aggregations tab. There are various design options and the first one that we are going to explore is the Aggregation Design Wizard.
At first we will just use the standard settings for Aggregation Design, and later we will customize and optimize our aggregation settings.
The first step in the wizard lets us review and change the Aggregation Usage.
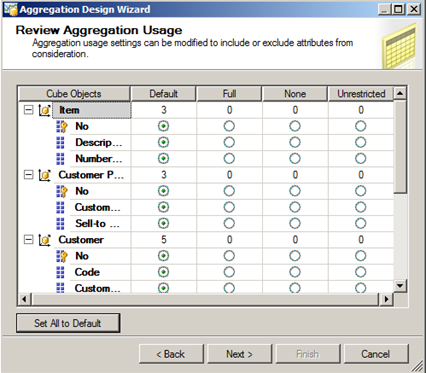
The meaning of the different AggregationUsage settings is explained here:
|
Full |
Every aggregation for the cube must include this attribute. |
|
None |
No aggregation for the cube should include this attribute. |
|
Unrestricted |
No restrictions are placed on the Aggregation Designer. |
|
Default |
Dependant on the attribute type. |
The Unrestricted setting may need some further explanation: When a dimension’s or an attribute’s AttributeUsage property has been set to Unrestricted, it is left to the Aggregation Designer to determine if the object should be included in an aggregation or not. The Aggregation Designer’s decision will be based on a cost/benefit analysis of each object.
A few rules of thumb apply when customizing the AggregationUsage property:
- Attributes that are hidden and not used in any custom dimension hierarchy should be set to None.
- Attributes that are frequently used, either as a stand-alone attribute or as part of a custom dimension hierarchy, should be set to Full.
- All others should be set to Unrestricted.
For now, we will leave the radio buttons at default and move on, clicking next.
On the Specify Objects Counts page, simply click the Count button.
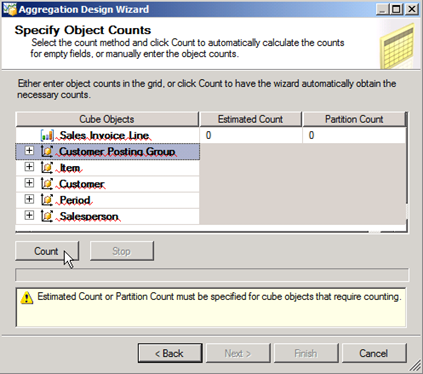
Use this step to automatically calculate the count of objects in the cube or to manually enter estimated counts. During the design process, the Aggregation Design Wizard uses the object counts to estimate and optimize storage requirements.
If you click Count the Transactions will be counted – however if you have a very large Fact Table you can just type in an estimated Count and move on.
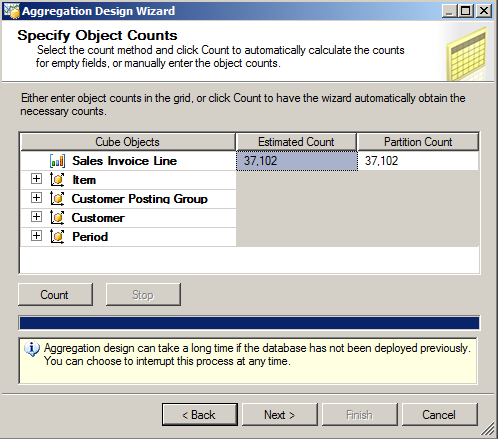
In the screenshot above we should notice that the fact table, Transact, contains 37102 transactions or records.
We should also notice that only two attributes of the Customer dimension have been counted even though we have three attributes in our dimension, in this case it is the Key Attribute, No, and the top level attribute, Country Name, of our custom hierarchy.

The importance of this is that only bold attributes will be considered for the following aggregation design.
Later we will see how we can tune our dimensions and force the Aggregation Designer to include or ignore an attribute.
On the Set Aggregation Options page, we have several options for controlling the number of aggregations. The optimal outcome is to achieve as high an Optimization level as possible, which will usually mean to have as many aggregations as possible, using as little physical storage space as possible.
Since we don’t know which aggregations the Aggregation Designer will choose, it may be tempting to let it design as many aggregations as possible. However, the result may then be too many aggregations that are rarely or never queried.
So, as a rule of thumb, you will get good performance optimization, with not too many aggregations, if you choose performance gain to reach 30 % - in this case however we will ask for 100%.
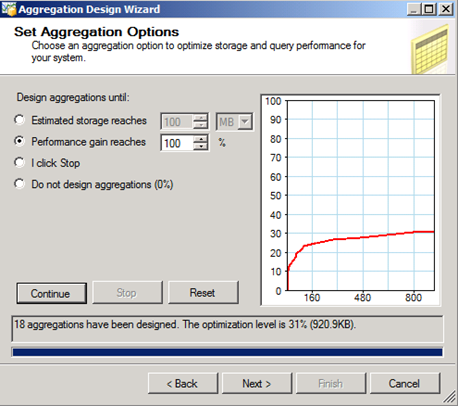
18 Aggregations were designed – the space used was 920 KB in this case. We click Next.
Now we name the Aggregation Design - move the radiobutton and choose to Deploy and Process right away. Click Finish.
On our list of Aggregation designs we see our recently generated AggregationDesign_100percent.
The Aggregation Design contains 18 aggregations and is currently assigned to the Sales Invoice Line Measure group.

Clicking the Advanced View button...

...and choosing AggregationDesign_ 100 percent from the Drop down we get to study what has been generated in this “black box”.
Expanding all of our Dimensions we get this overview:
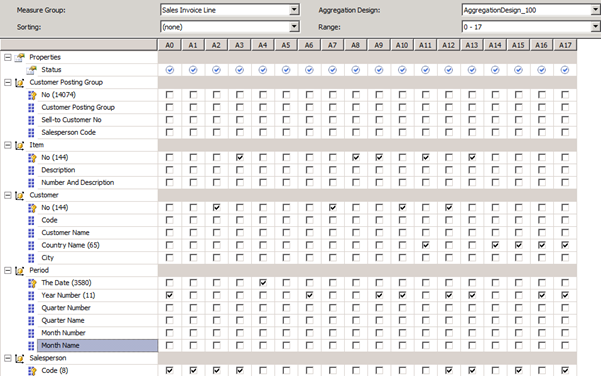
- Looking at the first aggregation (A0) we see that Years combined with Salesperson is now pre-summarized – so queries for e.g. Revenue per Year by Salesperson are fully optimized now
- A1 aggregates Salesperson alone. So a query for Cost per Salesperson will also be quite fast. The reason that Salesperson is preferred often in this wizard is probably that we only have 40 members of this Dimension so presummarizing Salespeople is not going to “explode” the size of the Cube
In this way we can study the choices made by the designer in great detail and in case we disagree remove checkmarks and set new ones according to our wishes.
In a production environment however, it is very important to be aware that Aggregations potentially takes up a lot of disk space – so caution is recommended when working with the Advanced View.
If you set checkmarks that are in some way inconsistent, you may experience the yellow warning sign:

The checkmark in Description should in this case be removed since it is redundant when Item No is checked.
It is also possible to delete/add aggreagation in this existing Aggregation design by right clicking and Choosing New Aggregation.
This will shift all the aggregations one number and the new aggregation will (a little confusing) be A0...
Comments
Please sign in to leave a comment.