As implied by its name, the Stage database will be used for staging the source data before further processing. Normally, the Stage database will be updated according to a fixed schedule with raw data from the source system(s).
It may seem a redundant task to simply move data from one database to another database. However, please keep in mind that in many live environments the source data may come from many different sources, in many different formats and from many different physical servers.
Some of the reasons for why you should have a Stage database are:
- Data should be moved away from the source system(s) as swiftly as possible – to reduce unnecessary load on these systems.
- The stage database may reside on a server that is highly optimized for data crunching.
- Only when data modifications have been completed on the stage database should data be moved (processed) to the final multidimensional Data Warehouse – to reserve and optimize the Data Warehouse server for Business Intelligence data requests.
In some environments you may see the Stage database strictly adhere to the rule of staging the source data. And when modifications are needed, these are done on a separate database or at least on a separate set of tables.
However, to keep things simple in our training environment we will create a Stage database that contains copied data from the relevant tables of our demo source data, and we will also use the Stage database when modifying these data to suit our Business Intelligence requirements, and after data modification the Stage database will eventually contain tables that are ready to be processed into a multi-dimensional database.
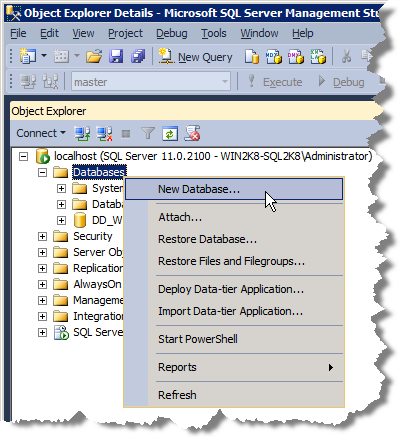
To create the Stage database simply right-click the Databases folder in SQL Server Management Studio.
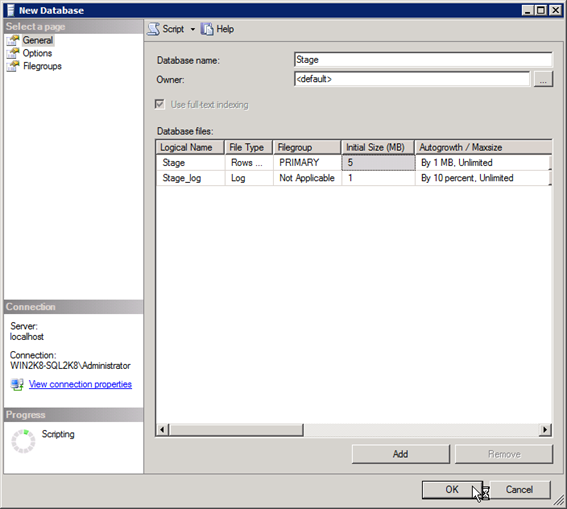
The new database can be named Stage and the other settings can be kept at their default settings for this course.
Comments
Please sign in to leave a comment.